

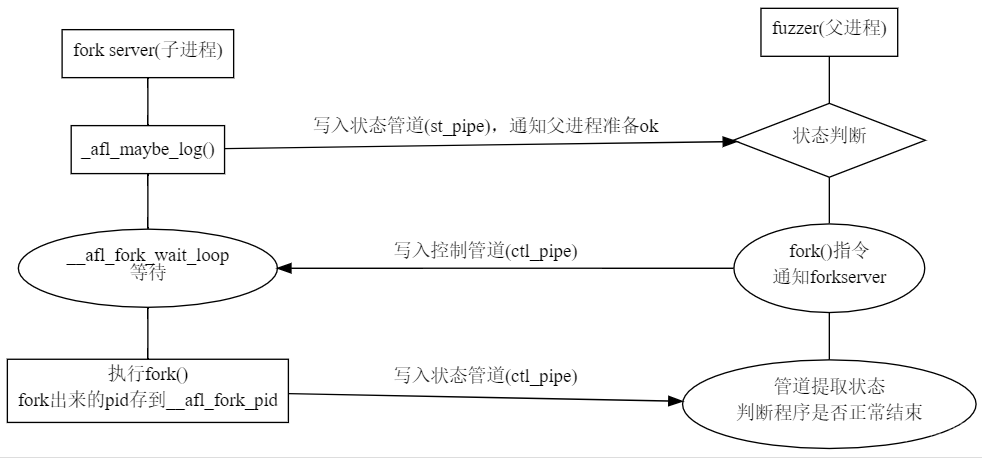
AFL作者用forserver架构进行开发。每次要进行测试的时候就fork出一个子进程进行测试,子进程复制父进程的数据段等,且拥有自己的PID,这就是进程的写时复制。
fuzzer->forkserver->exec target Bin->bin->bin_sub_process
1.afl-gcc.c
alf-gcc是gcc的一个封装(wrapper),能够实现对于一些关键节点进行插桩,从而记录一些程序执行路径之类的信息,方便对程序的一些运行情况进行反馈。
find_as
寻找afl-as的位置,检查afl_path/as这个文件是否可以访问,如果可以访问,就将afl_path设置为as_path。
edit_params
将argv拷贝到u8 **cc_params中,并做必要的编辑。

-B指定编译器路径,把汇编码给了afl-as。
main
find_as(argv[0])主要来查找汇编器edit_params(argc, argv)通过传入编译的参数来进行参数处理,将确定好的参数放入cc_params[]数组。- 在以上的步骤都完成之后,调用
execvp(cc_params[0], (char **) cc_params)执行afl-gcc。
输出

./afl-gcc ../test-instr.c -o test
afl-cc 2.57b by <lcamtuf@google.com>
arg0: gcc
arg1: ../test.c
arg2: -o
arg3: test
arg4: -B
arg5: .
arg6: -g
arg7: -O3
2.afl-as.c
此包装器的唯一目的是预处理生成的程序集文件。(用于插桩,插桩完毕之后用fork起子进程调用真正的汇编器。)
作者提到了需要插桩的部分有条件跳转和基本块。
检查并修改参数以传递给as。
涉及参数
- as_params:传递给as的参数。
- as_par_cnt:传递给“as”的参数数量初始值 。
- afl_as:as路径。
- modified_file:“as”进行插桩处理的文件。
edit_params
主要设置变量as_params的值,以及use_64bit/modified_file的值
- 设置
as_params[0]为afl_as - 遍历从argv[1]开始,到
argv[argc-1](最后一个参数)之前的argv参数,如果有--64,use_64bit为1,--32,use_64bit为0;as_params[as_par_cnt++] = argv[i];设置as_params的值为argv对应的参数值 - 设置modified_file的值为
alloc_printf("%s/.afl-%u-%u.s", tmp_dir, getpid(),(u32) time(NULL));,就是tmp_dir/.afl-pid-time.s这样的字符串。
主要函数add_instrumentation
处理输入文件,生成modified_file,将instrumentation插入所有适当的位置。只在.text部分进行插桩。
- 如果input_file不为空,则尝试打开这个文件,如果打开失败就抛出异常,如果为空,则读取标准输入,最终获取FILE* 指针inf
- 然后打开modified_file对应的临时文件,并获取其句柄outfd,再根据句柄通过fdopen函数拿到FILE*指针outf
- 通过fgets从inf中逐行读取内容保存到line数组里,每行最多读取的字节数是MAX_LINE(8192),这个值包括’\0’,所以实际读取的有内容的字节数是MAX_LINE-1个字节。从line数组里将读取的内容写入到outf对应的文件里。
关键代码如下:
///循环读取inf指向的文件的每一行到line数组,每行最多MAX_LINE(8192)个字节,含末尾“\0”
while (fgets(line, MAX_LINE, inf)) {
//检查instr_ok && instrument_next && line[0] == '\t' && isalpha(line[1])即判断instrument_next和instr_ok是否都为1,以及line是否以\t开始,且line[1]是否是字母
if(instr_ok && instrument_next && line[0] == '\t' && isalpha(line[1])){
//向outf中写入trampoline_fmt
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32,
R(MAP_SIZE));//插桩
instrument_next = 0;//instrument_next重新设置为0
ins_lines++;//插桩计数器+1
}
//是因为想要插入instrumentation trampoline到所有的标签,宏,注释之后
............................................................................................
//首先,只想检测.text部分。在已处理的文件中跟踪它,并相应地设置instr_ok[只有这个值被设置为1,才代表在.text部分,否则就不在;于是如果instr_ok为1,就会在分支处执行插桩逻辑,否则就不插桩。]。
//判断读入的行是否以“\t”开头,并且line[1]是否为"."
if (line[0] == '\t' && line[1] == '.') {
if (!strncmp(line + 2, "text\n", 5) ||
!strncmp(line + 2, "section\t.text", 13) ||
!strncmp(line + 2, "section\t__TEXT,__text", 21) ||
!strncmp(line + 2, "section __TEXT,__text", 21)) {
instr_ok = 1;
continue;
//匹配"text\n"、"section\t.text"、"section\t__TEXT,__text"、"section __TEXT,__text",如果匹配成功则设置instr_ok为1。然后跳转到while循环首部,去读取下一行的数据到line数组里。
}
if (!strncmp(line + 2, "section\t", 8) ||
!strncmp(line + 2, "section ", 8) ||
!strncmp(line + 2, "bss\n", 4) ||
!strncmp(line + 2, "data\n", 5)) {
instr_ok = 0;
continue;
//匹配"section\t"、"section "、"bss\n"、"data\n",如果匹配成功说明不是在.text段,设置instr_ok变量为0,并跳转到while循环首部,去读取下一行的数据到line数组里。
}
}
............................................................................................
//插桩^\tjnz foo条件跳转指令;将检测附加在分支之后(以检测未使用的路径)和分支目标标签(稍后处理)。
if (line[0] == '\t') {
//对于形如\tj[!m].格式的指令,即条件跳转指令,且R()函数创建的随机数小于插桩密度inst_ratio[R(100)会返回一个100以内的随机数]
if (line[1] == 'j' && line[2] != 'm' && R(100) < inst_ratio) {
//判断是否为64位程序,使用fprintf函数将桩插在outf只想的文件的\tj[^m].跳转指令位置,插入长度为R函数创建的小于MAP_SIZE的随机数
//[根据use_64bit来判断向outfd里写入trampoline_fmt_64还是trampoline_fmt_32。]
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32,
R(MAP_SIZE));//[R(x)实际上是用来区分每个桩的,也就是是一个标识。]
//插桩计数器+1,跳出循环进行下一次遍历
ins_lines++;
}
continue;
}
............................................................................................
//检查line中是否存在“:”
if (strstr(line, ":")) {
//检查是否以“.”开始
if (line[0] == '.') {
//检查line[2]是否为数字,或者在clang模式下从line[1]开始的三个字节是否为LBB,并且随机数小于插桩密度
if ((isdigit(line[2]) || (clang_mode && !strncmp(line + 1, "LBB", 3)))
&& R(100) < inst_ratio) {
//如果结果为真,则设置instrument_next = 1
instrument_next = 1;
}
}
else {
/* Function label (always instrumented, deferred mode). */
//否则代表这是一个function label,插桩^func,设置instrument_next为1(defered mode)
instrument_next = 1;
}
}
}
如果插桩计数器ins_lines不为0,就在完全拷贝input_file之后,依据架构,向outf中写入main_payload_64或者main_payload_32,然后关闭这两个文件。
afl的插桩就是通过汇编的前导命令来判断这是否是一个分支或者函数,然后插入instrumentation trampoline。
main
- main函数中将inst_ratio除3,因为AFL无法在插桩的时候识别出ASAN specific branches,所以会插入很多无意义的桩,为了降低这种概率,粗暴的将整个插桩的概率都除以3。
- edit_params
- add_instrumentation
- fork出一个子进程,让子进程来执行
execvp(as_params[0], (char **) as_params);
输出
3.afl-fuzz.c
main函数
前置工作
获取时间/扔随机数种子/解析参数/设置异常处理/设置环境变量/设置banner/检查终端/获取CPU核数
首先调用gettimeofday获取当前时间,然后调用srandom根据这个时间与当前进程的pid做亦或之后设定了种子:
gettimeofday(&tv, &tz); srandom(tv.tv_sec ^ tv.tv_usec ^ getpid());
进入到While大循环:
//通过 getopt 扫描 argv 里的参数。(比如afl-fuzz -i input -o output -- ./test)
while ((opt = getopt(argc, argv, "+i:o:f:m:b:t:T:dnCB:S:M:x:QV")) > 0)
switch (opt) {
case 'i': /* input dir */
//将 -i 后面的 input 赋值给 in_dir。
if (in_dir) FATAL("Multiple -i options not supported");
in_dir = optarg;
//如果此时的 in_dir = "-",那么设置 - in_place_resume = 1
if (!strcmp(in_dir, "-")) in_place_resume = 1;
break;
case 'o': /* output dir */
//将 -o 的参数output赋值给out_dir
if (out_dir) FATAL("Multiple -o options not supported");
out_dir = optarg;
break;
............................................................................................
调用 setup_signal_handlers() 设置信号处理的句柄
然后调用 check_asan_opts() 检测asan设置是否正确。[快速的内存错误检测工具]
如果设置了 sync_id = N ,那么在 fix_up_sync 中检测是否有互斥的参数、N是否过大。
setup_signal_handlers(); check_asan_opts(); if (sync_id) fix_up_sync();
如果设置了dumb_mode【Run in non-instrumented mode】,那么不能设置互斥的crash_mode和qemu_mode。
if (dumb_mode) {
if (crash_mode) FATAL("-C and -n are mutually exclusive");
if (qemu_mode) FATAL("-Q and -n are mutually exclusive");
}
获取环境变量:AFL_NO_FORKSRV、AFL_NO_CPU_RED、FL_NO_ARITH、AFL_SHUFFLE_QUEUE、AFL_FAST_CAL,设置对应的:no_forkserver、no_cpu_meter_red、no_arith、shuffle_queue、fast_cal=1。
if (getenv("AFL_NO_FORKSRV")) no_forkserver = 1;
if (getenv("AFL_NO_CPU_RED")) no_cpu_meter_red = 1;
if (getenv("AFL_NO_ARITH")) no_arith = 1;
if (getenv("AFL_SHUFFLE_QUEUE")) shuffle_queue = 1;
if (getenv("AFL_FAST_CAL")) fast_cal = 1;
通过AFL_HANG_TMOUT设置对应的hang_out时间。
if (getenv("AFL_HANG_TMOUT")) {
hang_tmout = atoi(getenv("AFL_HANG_TMOUT"));
if (!hang_tmout) FATAL("Invalid value of AFL_HANG_TMOUT");
}
保证dumb_mode == 2 与 no_forkserver的互斥
if (dumb_mode == 2 && no_forkserver)
FATAL("AFL_DUMB_FORKSRV and AFL_NO_FORKSRV are mutually exclusive");
//获取环境变量AFL_PRELOAD,设置LD_PRELOAD和DYLD_INSERT_LIBRARIES为AFL_PRELOAD。
if (getenv("AFL_PRELOAD")) {
setenv("LD_PRELOAD", getenv("AFL_PRELOAD"), 1);
setenv("DYLD_INSERT_LIBRARIES", getenv("AFL_PRELOAD"), 1);
}
//保存argv到局部变量buf中
save_cmdline(argc, argv);
//检测是否是终端环境
check_if_tty();
............................................................................................
// check_if_tty()
// 根据AFL_NO_UI设置not_on_tty = 1
if (getenv("AFL_NO_UI")) {
OKF("Disabling the UI because AFL_NO_UI is set.");
not_on_tty = 1;
return;
}
//通过IOCTL设置TIOCGWINSZ
if (ioctl(1, TIOCGWINSZ, &ws)) {
if (errno == ENOTTY) {
OKF("Looks like we're not running on a tty, so I'll be a bit less verbose.");
not_on_tty = 1;
}
............................................................................................
//获取cpu数量
get_core_count();
//根据亲缘性设置绑定CPU
bind_to_free_cpu();
//确保core dump的设置正确
check_crash_handling();
//初始化count_class_lookup16数组,在AFL中扮演的角色是统计遍历路径的数量
init_count_class16();
//准备输出文件目录(out_dir或sync_dir),创建plot_file
setup_dirs_fds();
//从输入(input)读取测试用例并入队,在启动时调用
read_testcases();
//load自动生成的提取出来的词典token
load_auto();
............................................................................................
//load_auto();
u8* fn = alloc_printf("%s/.state/auto_extras/auto_%06u", in_dir, i);
............................................................................................
//为input中的测试用例创建硬链接,选择名字
pivot_inputs();
//如果定义了extras_dir,则从extras_dir读取extras到extras数组里,并按size排序
if (extras_dir) load_extras(extras_dir);
//如果没设置timeout_given 那么调用 find_timeout 设置超时时间
if (!timeout_given) find_timeout();
//检查输入argv中是否存在@@,替换成out_dir/.cur_input
detect_file_args(argv + optind + 1);
//如果没有设置out_file,调用setup_stdio_file函数。如果没有使用-f,就删除原本的out_dir/.cur_input,创建一个新的out_dir/.cur_input,保存其文件描述符在out_fd中
if (!out_file) setup_stdio_file();
//检查指定路径要执行的程序是否存在,是否为shell脚本,同时检查elf文件头是否合法及程序是否被插桩。
check_binary(argv[optind]);
//获取当前时间
start_time = get_cur_time();
//如果是qemu_mode
if (qemu_mode)
//调用以下代码qemu重写参数
use_argv = get_qemu_argv(argv[0], argv + optind, argc - optind);
else
//如果不是
use_argv = argv + optind;
//执行所有的测试用例,以检查是否按预期工作,只执行一次
perform_dry_run(use_argv);
//精简队列
cull_queue();
//输出状态信息
show_init_stats();
//只有在恢复fuzz的时候起作用
seek_to = find_start_position();
............................................................................................
static u32 find_start_position(void) {
static u8 tmp[4096]; /* Ought to be enough for anybody. */
u8 *fn, *off;
s32 fd, i;
u32 ret;
if (!resuming_fuzz) return 0;
//如果设置了in_place_resume,打开out_dir/fuzzer_stats
if (in_place_resume) fn = alloc_printf("%s/fuzzer_stats", out_dir);
//否则打开in_dir/../fuzzer_stats
else fn = alloc_printf("%s/../fuzzer_stats", in_dir);
fd = open(fn, O_RDONLY);
ck_free(fn);
if (fd < 0) return 0;
//读取4095字节到tmp中
i = read(fd, tmp, sizeof(tmp) - 1); (void)i; /* Ignore errors */
close(fd);
//查找子串"cur_path : "的位置为off。
off = strstr(tmp, "cur_path : ");
if (!off) return 0;
//设置
ret = atoi(off + 20);
//如果ret >= queued_paths,将ret归零后return ret。
if (ret >= queued_paths) ret = 0;
return ret;
}
write_stats_file(0, 0, 0);更新统计信息文件以进行无人值守的监视
//保存自动生成的extras
//扫描a_extras[]数组,将对应的a_extras[i].data写入alloc_printf("%s/queue/.state/auto_extras/auto_%06u", out_dir, i),其中i最大是min(a_extras_cnt,USE_AUTO_EXTRAS)
save_auto();
//如果设置了stop_soon[就是是否Ctrl-C停止],跳转到stop_fuzzing
if (stop_soon) goto stop_fuzzing;
//如果是tty启动(终端),那么先sleep 4 秒,start_time += 4000。
if (!not_on_tty) {
sleep(4);
start_time += 4000;
if (stop_soon) goto stop_fuzzing;
}
主循环
主要的fuzz测试过程,主循环结束后会进行内存销毁、关闭文件描述符等收尾工作
while (1) {
u8 skipped_fuzz;
//首先精简队列
cull_queue();
//queue_cur指向当前队列中的元素。(entry)
//如果queue_cur为空,代表所有queue都被执行一轮
if (!queue_cur) {
queue_cycle++;//queue_cycle计数加一,说明走了一个循环了。
current_entry = 0;//归0
cur_skipped_paths = 0;//归0
queue_cur = queue;//queue_cur指向queue头,开始新一轮fuzz
//如果seek_to不为零。
//这个循环大概意思就是把queue_cur置位到seek_to的位置。
while (seek_to) {
current_entry++;//顺着队列持续后移
seek_to--;
queue_cur = queue_cur->next;
}
//展示状态
show_stats();
//如果不是终端模式,输出当前是第几个循环
if (not_on_tty) {
ACTF("Entering queue cycle %llu.", queue_cycle);
fflush(stdout);
}
//如果我们经历了一个完整的扫描周期后都没有新的路径发现,那么尝试调整策略。
/* If we had a full queue cycle with no new finds, try
recombination strategies next. */
if (queued_paths == prev_queued) {
//如果use_splicing为1,设置cycles_wo_finds计数器+1,记录本次扫描无新路径;否则设置use_splicing为1。(代表要通过splicing进行队列重组。)
if (use_splicing) cycles_wo_finds++; else use_splicing = 1;
//如果执行后和执行前路径数不一样,那么设置cycles_wo_finds为0
} else cycles_wo_finds = 0;
//新路径发现,更新“上一次”路径数
prev_queued = queued_paths;
//如果设置了sync_id并且queue_cycle == 1,并且环境变量中设置了AFL_IMPORT_FIRST
if (sync_id && queue_cycle == 1 && getenv("AFL_IMPORT_FIRST"))
//调用sync_fuzzers(use_argv)
sync_fuzzers(use_argv);
}
//调用fuzz_one(use_argv)对于我们的样本进行变换后fuzz,返回skipped_fuzz
skipped_fuzz = fuzz_one(use_argv);
//若skipped_fuzz为0,并且stop_soon为0,并且设置了sync_id
if (!stop_soon && sync_id && !skipped_fuzz) {
//若sync_interval_cnt没有到一个周期(% SYNC_INTERVAL)(对SYNC_INTERVAL(默认为5)求余,即如果是5的倍数)
if (!(sync_interval_cnt++ % SYNC_INTERVAL))
//调用sync_fuzzers(use_argv)同步其他fuzzer
sync_fuzzers(use_argv);
}
//如果没有设置stop_soon,且 exit_1不为0,那么设置stop_soon=2后break出fuzz主循环。
if (!stop_soon && exit_1) stop_soon = 2;
if (stop_soon) break;
//否则准备fuzz队列中下一个样本。
queue_cur = queue_cur->next;
//queue ID+1
current_entry++;
}
主循环函数fuzz_one(char **argv)
从队列中取出当前的一项,然后进行fuzz,返回0如果fuzz成功。返回1如果跳过或者bailed out。
- 如果设置了
pending_favored(看了一下这个参数是挂起的首选路径)if判断(当前case是否已经fuzz过了或者不是favored)并且产生一个100以内的随机数,如果小于SKIP_TO_NEW_PROB(默认99),return 1。 - 如果非dumb_mode(非仪表化模式),且当前的不是favored,并且queued_paths > 10
- 若queue_cycle > 1,并且当前的queue_cur还没有fuzz过。产生一个100以内的随机数,如果小于
SKIP_NFAV_NEW_PROB。(有75%的概率return 1(SKIP_NFAV_NEW_PROB默认为75)) - 否则产生一个100以内的随机数,如果小于
SKIP_NFAV_OLD_PROB。(有95%的概率return 1(SKIP_NFAV_OLD_PROB默认为95))
- 若queue_cycle > 1,并且当前的queue_cur还没有fuzz过。产生一个100以内的随机数,如果小于
- 如果不是tty模式。(终端) 输出
current_entry, queued_paths, unique_crashes提示信息,刷新stdout缓冲区。 - 将当前的test case映射进入内存。
orig_in = in_buf = mmap(0, len, PROT_READ | PROT_WRITE, MAP_PRIVATE, fd, 0) - 分配len大小空间,并初始化为全0,将空间首地址赋值给out_buf
- 设置连续超时次数
subseq_tmouts为0 - 设置
cur_depth为queue_cur->depth(当前路径深度)
CALIBRATION (only if failed earlier on)阶段
- 如果当前的
queue_cur->cal_failed不为0(存在校准错误)- 如果校准错误的次数小于三次。
- 重制exec_cksum来告诉
calibrate_case重新执行testcase来避免对于无效trace_bits的使用。 - 设置
queue_cur->exec_cksum为0. - 对于queue_cur重新执行
calibrate_case。res = calibrate_case(argv, queue_cur, in_buf, queue_cycle - 1, 0) - 如果返回值为FAULT_ERROR,那么直接abort
- 重制exec_cksum来告诉
- 如果设置了stop_soon,或者res不等于crash_mode。
- cur_skipped_paths计数加一。
- 跳转到
abandon_entry
- 如果校准错误的次数小于三次。
TRIMMING修剪阶段
- 如果不是dumb_mode且当前的没有经过trim(!queue_cur->trim_done)
- 调用
trim_case对当前项进行修建。返回restrim_case(argv, queue_cur, in_buf) - 如果res为FAULT_ERROR,直接abort
- 如果设置了stop_soon
- cur_skipped_paths计数加一。
- 跳转到abandon_entry
- 设置当前queue_cur为已经trim过。
queue_cur->trim_done = 1 - 如果len不等于queue_cur->len。
- 令len = queue_cur->len。
- 调用
- 将in_buf中的内容拷贝len到out_buf。
PERFORMANCE SCORE阶段
- 调用
calculate_score(queue_cur)计算当前queue_cur的score - 如果设置了skip_deterministic或者queue_cur->was_fuzzed(被fuzz过了)或者queue_cur->passed_det=1
- 直接goto havoc_stage
- 如果当前的
queue_cur->exec_cksum % master_max不等于master_id – 1,那么goto havoc_stage Skip deterministic fuzzing if exec path checksum puts this out of scope for this master instance.如果exec path校验和超出了此主实例的范围,请跳过确定性模糊化。 - 设置doing_det = 1
SIMPLE BITFLIP 位反转(+dictionary construction字典构造)阶段
stage_short="flip1"; stage_name="bitflip 1/1";
- 定义stage_max为len << 3
- stage_val_type为STAGE_VAL_NONE
- orig_hit_cnt为queued_paths + unique_crashes
- 而prev_cksum为queue_cur->exec_cksum
- 接下来进入一个for循环
for (stage_cur = 0; stage_cur < stage_max; stage_cur++) {
stage_cur_byte = stage_cur >> 3;
FLIP_BIT(out_buf, stage_cur);
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
FLIP_BIT(out_buf, stage_cur);
.......
}
这个循环中调用了FLIP_BIT(out_buf, stage_cur)
#define FLIP_BIT(_ar, _b) do { \
u8* _arf = (u8*)(_ar); \
u32 _bf = (_b); \
_arf[(_bf) >> 3] ^= (128 >> ((_bf) & 7)); \
} while (0)
(_bf) & 7)相当于模8,产生了(0、1、2、3、4、5、6、7)- 128是二进制的10000000.
- 等式的右边相当于将128右移动0-7个单位产生了二进制从(10000000 – 1)
(_bf) >> 3相当于_bf/8- stage_cur最大为stage_max相当于len << 3
- 所以对于
FLIP_BIT(_ar, _b)来说,_bf最大为(len << 3)>>3还是len - 也就是说,对于这个for循环来说,每运行8次循环
_arf[i](大小为一个字节)的下标i就会加一,i最大为len。 - 同时在每8次为一组的循环中,128分别右移0、1、2、3、4、5、6、7位,将右移后产生的数字与
_arf[i]进行异或翻转,而_arf[i]大小为一个字节,等价于对这个字节的每一位都做一次翻转异或
- 当这一位被异或完毕后,调用
common_fuzz_stuff(argv, out_buf, len)进行fuzz。- 如果返回1,
goto abandon_entry
- 如果返回1,
- 最后再调用一次
FLIP_BIT(out_buf, stage_cur)异或翻转回来。 - 这一部分代码中给出了注释进行解释: 比如说对于一串二进制: xxxxxxxxIHDRxxxxxxxx 当我们改变IHDR中的任意一个都会导致路径的改变or破坏, “IHDR”就像在二进制串中的一整体的具有原子性的可检查的特殊值(原语?)。“IHDR” is an atomically-checked magic value of special significance to the fuzzed format.,afl希望能找到这些值。
- 如果不是dumb_mode且stage_cur & 7不等于7
- 计算当前trace_bits的hash32为cksum
- 如果当前到达最后一轮循环并且cksum == prev_cksum
- 如果a_len小于MAX_AUTO_EXTRA
- 令
a_collect[a_len]为out_buf[stage_cur >> 3] - a_len递增1
- 令
- 如果a_len 在MIN_AUTO_EXTRA与MAX_AUTO_EXTRA之间
- 调用
maybe_add_auto(a_collect, a_len)
- 调用
- 如果a_len小于MAX_AUTO_EXTRA
- 如果cksum != prev_cksum
- 如果a_len 在MIN_AUTO_EXTRA与MAX_AUTO_EXTRA之间
- 调用
maybe_add_auto(a_collect, a_len)将发现的新token加入a_extra[]
- 调用
- a_len归零
- 令prev_cksum = cksum
- 如果a_len 在MIN_AUTO_EXTRA与MAX_AUTO_EXTRA之间
- 如果cksum != queue_cur->exec_cksum
- 若a_len < MAX_AUTO_EXTRA
- a_collect[a_len] = out_buf[stage_cur >> 3]
- a_len递增1.
- 若a_len < MAX_AUTO_EXTRA
接下来进入bitflip 2/1
- 保存当前new_hit_cnt到orig_hit_cnt。
- 经过一个for循环做bit flip和样例运行。
stage_name = "bitflip 2/1";
stage_short = "flip2";
stage_max = (len << 3) - 1;
orig_hit_cnt = new_hit_cnt;
for (stage_cur = 0; stage_cur < stage_max; stage_cur++) {
stage_cur_byte = stage_cur >> 3;
FLIP_BIT(out_buf, stage_cur);
FLIP_BIT(out_buf, stage_cur + 1);
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
FLIP_BIT(out_buf, stage_cur);
FLIP_BIT(out_buf, stage_cur + 1);
}
- 这一次唯一的不同是是每次连续异或翻转两个bit。
- 翻转结束后更新new_hit_cnt
- 更新
stage_finds[STAGE_FLIP2]与stage_cycles[STAGE_FLIP2] - 接下来同样的进入
bitflip 4/1,连续翻转4次 - 生成Effector map
/* Effector map setup. These macros calculate: EFF_APOS - position of a particular file offset in the map. EFF_ALEN - length of a map with a particular number of bytes. EFF_SPAN_ALEN - map span for a sequence of bytes. */ #define EFF_APOS(_p) ((_p) >> EFF_MAP_SCALE2) #define EFF_REM(_x) ((_x) & ((1 << EFF_MAP_SCALE2) - 1)) #define EFF_ALEN(_l) (EFF_APOS(_l) + !!EFF_REM(_l)) #define EFF_SPAN_ALEN(_p, _l) (EFF_APOS((_p) + (_l) - 1) - EFF_APOS(_p) + 1)
- 首先分配len大小的空间eff_map
- 将eff_map[0]初始化为1;将eff_map[(len – 1)>>3]初始化为1(及第一项和最后一项)
进入"bitflip 8/8"阶段
- 本阶段有一个很重要的思想:我们通过对于 out_buf所有bit进行异或翻转,如果产生了不一样的路径,就在eff_map中标记为1,否则为0。因为如果对所有bit都做翻转还无法带来相关的路径变化,afl认为在后续的一些开销更大的阶段,参考eff_map,可以对这些无效的byte进行跳过。减小开销。
- 这个阶段中不是通过FILP宏来做翻转,而是直接与0xff做异或。
for (stage_cur = 0; stage_cur < stage_max; stage_cur++) {
stage_cur_byte = stage_cur;
out_buf[stage_cur] ^= 0xFF; //直接通过对于out_buf的每一个字节中的每一个bit做异或翻转。
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry; //运行对应的test case(翻转后)
if (!eff_map[EFF_APOS(stage_cur)]) { //如果eff_map[stage_cur>>3]为0的话
//EFF_APOS宏也起到了一个将stage_cur>>3的效果
u32 cksum;
/* If in dumb mode or if the file is very short, just flag everything
without wasting time on checksums. */
if (!dumb_mode && len >= EFF_MIN_LEN)//如果不是dumb_mode且len大于最小的EFF_MIN_LEN
cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST);//计算hash32
else //否则,如果是dumb mode或者len过小
cksum = ~queue_cur->exec_cksum;
if (cksum != queue_cur->exec_cksum) {
eff_map[EFF_APOS(stage_cur)] = 1;//产生新的路径,发生了变化,此时直接将对应的eff_map中的项标记为1
eff_cnt++;
}
}
out_buf[stage_cur] ^= 0xFF;//从新异或回来
}
- 如果eff_map的密度超过了EFF_MAX_PERC,那么将整个eff_map都标记为1(即使不这样做,我们也不会省很多时间)
- 更新new_hit_cnt、stage_finds[STAGE_FLIP8]、stage_cycles[STAGE_FLIP8]
- 如果len<2,直接跳到
skip_bitflip
- 进入
"bitflip 16/8"- 唯一不同的是,在异或变异之前先检查了对应的eff_map的对应两个字节是否为0
- 如果是0,
stage_max计数减1.然后continue跳过。 - 否则进行异或翻转后运行。
- 如果是0,
- 唯一不同的是,在异或变异之前先检查了对应的eff_map的对应两个字节是否为0
- 更新new_hit_cnt、stage_finds[STAGE_FLIP16]、stage_cycles[STAGE_FLIP16]
- 如果len<4,跳转到skip_bitflip
- 接下来是
"bitflip 32/8",与上述基本相同。 -如果设置了```no_arith- goto
skip_arith
- goto
ARITHMETIC INC/DEC 阶段(做加减变异)
#define ARITH_MAX 35"arith 8/8"以byte为单元变异阶段
- 首先扫描out_buf。
u8 orig = out_buf[i](此时一个orig是一个字节,此阶段是按字节扫描) - 如果对应的eff_map中的项为0,则stage_max减去2倍的ARITH_MAX,然后continue跳过此次变异
- 否则进入一个for循环进行变异->运行
//依次扫描orig到orig+35
for (j = 1; j <= ARITH_MAX; j++) {
//将orig与orig+j(j最大为35)进行异或翻转
u8 r = orig ^ (orig + j);
/* Do arithmetic operations only if the result couldn't be a product
of a bitflip. */
//判断是否为可以通过上一阶段bitfilp得到的(这一步是为了防止相同的冗余变异,节省时间)
if (!could_be_bitflip(r)) {
stage_cur_val = j;
//将out_buf[i]本身加j变异
out_buf[i] = orig + j;
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;//进行fuzz
stage_cur++;
} else stage_max--; //否则stage_max减1
//将orig与orig-j(j最大为35)进行异或翻转
r = orig ^ (orig - j);
//同上
if (!could_be_bitflip(r)) {
stage_cur_val = -j;
//将out_buf[i]本身减j变异
out_buf[i] = orig - j;
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;
stage_cur++;
} else stage_max--;
out_buf[i] = orig;
}
"arith 16/8"阶段- 此时以2个字节(word)为单位进行加减变异,并且对于大端序与小端序都进行变异。
"arith 32/8"阶段- 以4个字节(32bits)为单位进行加减变异,并且对于大端序与小端序都进行变异。
INTERESTING VALUES阶段(替换变异)
- 首先是
"interest 8/8"阶段,以一个字节为单位进行替换变异- 本阶段首先通过
could_be_bitflip(orig ^ (u8) interesting_8[j])||could_be_arith(orig, (u8) interesting_8[j], 1))保证替换不会由前面的异或和加减变异阶段得到(本质是在防止冗余变换,减小开销) - 然后通过
out_buf[i] = interesting_8[j]进行一个字节的替换。 - 之后调用
common_fuzz_stuff(argv, out_buf, len)进行fuzz
- 本阶段首先通过
"interest 16/8"阶段,以两个字节为单位进行替换变异,并且去除异或、加减、与单字节变异阶段的冗余,同时考虑大小端序。"interest 32/8"阶段(4字节为单位替换变异)与前面类似。
DICTIONARY STUFF阶段(基于用户提供的extra来进行一定的变异)
"user extras (over)"替换阶段- 在满足一定大小的条件下(同时有一定随机性),将用户的extra token以memcpy的方式替换/覆写(over)进去,然后进行fuzz
memcpy(out_buf + i, extras[j].data, last_len);
if (common_fuzz_stuff(argv, out_buf, len)) goto abandon_entry;- 最后在进行恢复。
"user extras (insert)"插入阶段- 插入(insert)用户的extras[j],然后产生一个新的ex_tmp,对于这个ex_tmp进行fuzz。
"auto extras (over)"替换阶段2- 本阶段类似于over,只不过用于替换的变成了
a_extras[j]而非extras[j] - 接下来到达标签:
skip_extras:,如果我们在不跳至havoc_stage或abandon_entry的情况下来到这里,说明我们已经正确的完成了确定的fuzz(deterministic steps)步骤,我们可以对其进行标记如 .state/ 目录- 如果没有设置
queue_cur->passed_det:- 调用
mark_as_det_done(queue_cur)进行标记。
- 调用
- 如果没有设置
RANDOM HAVOC(随机毁灭)阶段(大范围随机变异)
- 首先检测如果没有设置
splice_cycle- 那么标记此阶段为
"havoc"
- 那么标记此阶段为
- 否则标记此阶段为
"splice" - 设置stage_max
- 在每一轮stage中首先产生随机数
use_stacking - 根据产生的
use_stacking做相应次数的变换。相当于每一轮stage中具体的变换由多次小变化叠加产生。 - 每次变换具体的内容也由一个随机数决定。
UR(15 + ((extras_cnt + a_extras_cnt) ? 2 : 0))- 随机替换一个
interesting_8[]中的byte进来 - 随机替换
interesting_16[]中的某个word进来(大小端序随机选择) - 随机替换
interesting_32[]中的某个dword进来(大小端序随机选择) - 随机选取
out_buf[]中某个byte进行减变异(减随机数) - 随机选取
out_buf[]中某个byte进行加变异(加随机数) - 随机选取
out_buf[]中某个word进行减变异(减随机数,大小端序随机选择) - 随机选取
out_buf[]中某个word进行加变异(加随机数,大小端序随机选择) - 随机选取
out_buf[]中某个dword进行减变异(减随机数,大小端序随机选择) - 随机选取
out_buf[]中某个dword进行加变异(加随机数,大小端序随机选择) - 随机选取
out_buf[]中某个byte进行异或翻转变异 - 随机选取
out_buf[]中某个byte进行删除- 随机选取
out_buf[]中某个位置插入一段随机长度clone_to = UR(temp_len)的内容。这段内容有75%的概率是原来out_buf[]中的内容;有25%的概率是一段相同的随机选取的数字。(这串随机选取的数字有50%的几率随机生成,有50%的几率从out_buf中选一个字节)
- 随机选取
- 随机选取
out_buf[]中某个位置覆写一段随机长度的内容。这段内容有75%的概率是原来out_buf[]中的内容;有25%的概率是一段相同的随机选取的数字。(这串随机选取的数字有50%的几率随机生成,有50%的几率从out_buf中选一个字节) - 随机选取一段内容覆写成extra token
a_extras[use_extra].data或者extras[use_extra].data - 随机选取一段内容插入extra token
a_extras[use_extra].data或者extras[use_extra].data
- 随机替换一个
- 在每一轮stage中首先产生随机数
SPLICING阶段(拼接)
- 当没有
define IGNORE_FINDS时。如果经过了一整轮什么都没有发现,那么afl会进入retry_splicing:这里进一步的对于输入样本进行变换,通过拼接另一个输入样本来完成此变换,最后又跳回havoc_stage上一阶段进行大范围的随机变换。 - 否则设置
ret_val = 0 - 到达
abandon_entry: - 设置
splicing_with = -1 - 对于队列当前项信息更新。
- 如果未设置stop_soon且queue_cur->cal_failed为0,queue_cur->was_fuzzed未被标记已经fuzz过。
- 标记queue_cur->was_fuzzed为已经fuzz过了
- pending_not_fuzzed计数减1
- 如果当前对象是favored,那么pending_favored计数也减1
- 如果未设置stop_soon且queue_cur->cal_failed为0,queue_cur->was_fuzzed未被标记已经fuzz过。
- return ret_val
- fuzz_one结束。
sync_fuzzers
Grab interesting test cases from other fuzzers抓取其他fuzzer的case。
该函数会首先查找有哪些fuzzer文件夹,然后读取其他fuzzer文件夹下的queue文件夹里的case,依次执行一遍,如果发现了新的path,就保存到自己的queue文件夹里,将最后一个sync的case id写入到.synced/其他fuzzer文件名文件里
- 首先打开目录
sync_dir - 接着进入大循环,
while ((sd_ent = readdir(sd))),readdir()返回参数dir 目录流的下个目录进入点,返回一个指向struct dirent的指针sd_ent,循环遍历sync_dir目录下的所有文件(其他fuzzer创建的)- 首先跳过
.文件还有我们自己fuzzer的输出文件(sync_id(输出文件夹))。 - 接着打开
"sync_dir/sd_ent->d_name/queue"目录。 - 检索最后看到的测试用例的ID。
- 打开
out_dir/.synced/sd_ent->d_name,返回值赋予id_fd。 - 接着从打开的id_fd读取4个字节到
min_accept。 - 如果成功读取,调动lseek函数调整文件内指针到开头
- 更新
next_min_accept为我们刚刚读取的min_accept,该变量代表之前从这个文件夹里读取到的最后一个queue的id。 sync_cnt计数加一,由”sync %u”格式化到stage_tmp中。- 设置
stage_cur = stage_max = 0 - 接下来一个小的while循环
while ((qd_ent = readdir(qd)))读取sync_dir/sd_ent->d_name/queue文件夹中的目录和文件,解析ID并查看我们之前是否曾看过它; 如果没有,执行此个测试用例。- 若文件以’.’开头,或者
syncing_case < min_accept或者(这些文件已经被sync过了);或者我们使用sscanf(qd_ent->d_name, CASE_PREFIX "%06u", &syncing_case)失败返回-1。直接跳过此次case的扫描。 - 如果
syncing_case >= next_min_accept- 设置
next_min_accept为syncing_case + 1
- 设置
- 打开
qd_path/qd_ent->d_name返回值赋予fd。 - 忽略大小为0和超过大小的文件。
- 将fd对应的文件映射到进程空间中,返回
u8 *mem - 看看会发生什么,依靠save_if_interesting()来捕捉主要的错误并保存测试案例。
- 调用
write_to_testcase(mem, st.st_size)将其写到outfile中。 - 接着
run_target运行对应文件,返回fault。 - 如果设置了stop_soon,直接返回。
- 将
syncing_party置为sd_ent->d_name - 调用
save_if_interesting(argv, mem, st.st_size, fault)来决定是否要将这个queue导入到自己的queue里,如果发现了新的path,就导入;如果返回值为1,则queued_imported计数器+1 - 设置
syncing_party = 0 - 调用
munmap(mem, st.st_size)接触映射。 - 然后
stage_cur++ % stats_update_freq如果是0即循环到一个周期,那么输出对应的fuzz信息。
- 若文件以’.’开头,或者
- 将
&next_min_accept对应文件中的内容写到id_fd对应的文件中。 - 关闭对应的文件/目录描述等。
- 首先跳过
save_if_interesting(char *argv, void mem, u32 len, u8 fault)
检查这个case的执行结果是否是interesting的,决定是否保存或跳过。若需要返回1,否则返回0。
- 如果fault为crash_mode模式/只有在map0上有新的bits才保留,添加到队列中以便未来的模糊处理/
- 查看此时是否出现了newbits。
- 如果没有的话若设置了crash_mode,则total_crashes计数加一。
- 否则直接return 0;
- 若出现了newbits则调用
fn = alloc_printf("%s/queue/id:%06u,%s", out_dir, queued_paths,describe_op(hnb));拼接出路径fn=out_dir/queue/id:00000queued_paths,describe_op(hnb) - 通过调用
add_to_queue(fn, len, 0)将其插入队列。 - 如果
hnb==2成立。(有新路径发现)- 设置
queue_top->has_new_cov为1。同时queued_with_cov(覆盖范围)计数加一。
- 设置
- 利用hash32从新计算trace_bits的哈希值,将其设置为
queue_top->exec_cksum/尝试校准;当成功时调用update_bitmap_score()。/ - 调用
calibrate_case进行用例校准,评估当前队列。- 如果校验返回值为FAULT_ERROR,抛异常
- 打开fn,将mem的内容写入文件fn。
- 设置keeping = 1.
- 查看此时是否出现了newbits。
- 接下来通过switch来判断fault类型。
- fault == FAULT_TMOUT/超时并不十分有趣,但我们仍有义务保留一些少量的样本。我们使用特定于挂起的位图中存在的新位作为唯一性的信号。在“dumb”模式下,我们只保留一切。/
- 首先
total_tmouts计数加一。 - 如果unique_hangs的个数超过能保存的最大数量KEEP_UNIQUE_HANG(默认为500)直接返回keeping
- 如果不是dumb_mode
- 调用
simplify_trace对trace_bits进行调整。 - 若没有新的超时路径
if (!has_new_bits(virgin_tmout)),直接return keeping。- unique_tmouts计数加一。/在保存之前,我们要确保这是一个真正的挂起,通过重新运行来确保它是真正的挂起/
- 如果
exec_tmout小于hang_tmout- 将mem的内容写到outfile。
- 然后再次调用
run_target运行一次,返回new_fault。 - 如果没有发生主动中断,并且new_fault的结果为FAULT_CRASH,那么直接跳转到keep_as_crash
- 如果设置了
stop_soon发生主动中断或者new_fault的结果不为FAULT_CRASH,直接返回keeping
- 拼接出路径:
fn = alloc_printf("%s/hangs/id:%06llu,%s", out_dir,unique_hangs, describe_op(0)); unique_hangs计数加一。- 通过
get_cur_time()获取last_hang_time - break;
- 首先
- fault == FAULT_CRASH
- total_crashes计数加一。
- 如果unique_crashes数量大于等于能保存的最大数量KEEP_UNIQUE_CRASH(默认5000) 直接返回keeping
- 如果不是dumb_mode
- 调用simplify_trace规整trace_bits【带有仪表位图的 SHM】
- 若没有新的crash路径,直接return keeping。
- 如果unique_crashes=0
- 调用
write_crash_readme()编写崩溃目录信息
- 调用
- 拼接出路径:
fn = alloc_printf("%s/crashes/id:%06llu,sig:%02u,%s", out_dir,unique_crashes, kill_signal, describe_op(0)); unique_crashes计数加一。- 获取当前时间为last_crash_time。
- 令last_crash_execs为total_execs。
- break
FAULT_ERROR- 输出提示信息后直接abort。
default:- 返回keeping。
- fault == FAULT_TMOUT/超时并不十分有趣,但我们仍有义务保留一些少量的样本。我们使用特定于挂起的位图中存在的新位作为唯一性的信号。在“dumb”模式下,我们只保留一切。/
- 接下来将mem中的内容写出到文件fn中。
- return keeping。
trim_case(char **argv, struct queue_entry *q, u8 *in_buf)
之前TRIMMING修剪阶段中一开始调用的函数,对case进行修剪。
- 如果过当前队列case的len<5,那么直接return 0,就不需要修剪了;
- 令stage_name指向tmp数组首位。bytes_trim_in计数加上当前的q->len。/选择初始块 len/
- 接着找出使得2^x > q->len的最小的x,作为len_p2。
len_p2 = next_p2(q->len) - 设置remove_len为
MAX(len_p2 / TRIM_START_STEPS, TRIM_MIN_BYTES)即len_p2/16,与4中最大的那个,作为步长。 - 通过一个while循环调整步长,直到变得太长或太短。
while (remove_len >= MAX(len_p2 / TRIM_END_STEPS, TRIM_MIN_BYTES))如果remove_len大于等于(len_p2/1024)和(4)之间最大的(每轮remove_len/2)- 首先令
remove_pos = remove_len - 通过
sprintf格式化remove_len到tmp中。 - 令当前的stage_cur为0, stage_max为
q->len / remove_len - 进入一个while循环
while (remove_pos < q->len)/循环每次前进remove_len个步长,直到整个文件都被遍历完为止/- 令
trim_avail = MIN(remove_len, q->len - remove_pos) - 调用
write_with_gap(由in_buf中的remove_pos处开始,向后跳过remove_len个字节,写入到.cur_input中) - 接着
run_target运行此样例,返回fault。 trim_execs计数加一。- 如果设置了stop_soon或者fault == FAULT_ERROR,直接跳转到
abort_trimming - 计算当前trace_bits的hash32为cksum。
- 如果当前的q->exec_cksum与计算出来的cksum相等。
- 令
move_tail为q->len – remove_pos – trim_avail。 - q->len减去trim_avail
- 重新计算当前的
len_p2 = next_p2(q->len) - 将
in_buf + remove_pos + trim_avail到最后的字节前移到in_buf + remove_pos处,即删除了remove_pos向后的remove_len个字节 - 如果
needs_write为0.- 设置
needs_write = 1 - 保存当前的trace_bits到clean_trace中
- 设置
- 令
- 如果不等,remove_pos累加remove_len,即前移remove_len个字节,如果相等则无需前移。
- 如果trim的次数到达一个周期,那么输出信息。
stage_cur计数加一。
- 令
remove_len减半
- 首先令
- 如果设置了needs_write(在当前的q->exec_cksum与计算出来的cksum相等那一步设置)
- 打开q->fname对应的文件。
- 将in_buf中的内容写出到q->fname文件
- 拷贝clean_trace到trace_bits
- 调用
update_bitmap_score(q)更新此时的bitmap信息。
abort_trimming:- bytes_trim_out加上q->len
- return fault。
simplify_trace(u64 *mem)
之前调用simplify_trace规整trace_bits【带有仪表位图的 SHM】,
/通过消除命中计数信息并根据元组是否命中将其替换为 0x80 或 0x01 来破坏性地简化跟踪。 在每次新的崩溃或超时时调用,应该相当快。/
static const u8 simplify_lookup[256] = {
[0] = 1,
[1 ... 255] = 128
};
#ifdef WORD_SIZE_64
//8个bytes为一组扫描整个mem(trace_bits)
static void simplify_trace(u64* mem) {
u32 i = MAP_SIZE >> 3;
while (i--) {
/* Optimize for sparse bitmaps. */
//如果当前这一组*mem不空
if (unlikely(*mem)) {
u8* mem8 = (u8*)mem;
//取simplify_lookup[mem8[i]]放入mem8[i],代表当命中了(mem8[i]=1)时,对应的是mem8[i]被设置为128。(0b10000000)没命中被设置为mem8[i]被设置为1。
mem8[0] = simplify_lookup[mem8[0]];
mem8[1] = simplify_lookup[mem8[1]];
mem8[2] = simplify_lookup[mem8[2]];
mem8[3] = simplify_lookup[mem8[3]];
mem8[4] = simplify_lookup[mem8[4]];
mem8[5] = simplify_lookup[mem8[5]];
mem8[6] = simplify_lookup[mem8[6]];
mem8[7] = simplify_lookup[mem8[7]];
} //不然的话,设置这一组为0x0101010101010101,代表都没有命中,每个字节被置1.
else *mem = 0x0101010101010101ULL;
//mem++,后移到下一组。
mem++;
}
}
calculate_score(struct queue_entry *q)
根据queue entry的执行速度、覆盖到的path数和路径深度来评估出一个得分,这个得分perf_score在后面havoc的时候使用,应该是这个地方:

- 首先计算平均时间
avg_exec_us = total_cal_us / total_cal_cycles - 计算平均bitmap大小
avg_bitmap_size = total_bitmap_size / total_bitmap_entries - 定义初始的
perf_score = 100 - 接下来通过给q->exec_us乘一个系数,判断他和avg_exec_us的大小来调整perf_score。
//与全球平均水平相比,根据此路径的执行速度调整分数。 乘数范围从 0.1x 到 3x。 快速输入的 fuzz 成本更低,因此我们给了它们更多的播放时间。 if (q->exec_us * 0.1 > avg_exec_us) perf_score = 10; else if (q->exec_us * 0.25 > avg_exec_us) perf_score = 25; else if (q->exec_us * 0.5 > avg_exec_us) perf_score = 50; else if (q->exec_us * 0.75 > avg_exec_us) perf_score = 75; else if (q->exec_us * 4 < avg_exec_us) perf_score = 300; else if (q->exec_us * 3 < avg_exec_us) perf_score = 200; else if (q->exec_us * 2 < avg_exec_us) perf_score = 150;
- 然后通过给q->bitmap_size 乘一个系数,判断与avg_bitmap_size的大小关系来调整perf_score。
//根据位图大小调整分数。 工作原理是,更好的覆盖范围可以转化为更好的目标。 乘数从 0.25x 到 3x if (q->bitmap_size * 0.3 > avg_bitmap_size) perf_score *= 3; else if (q->bitmap_size * 0.5 > avg_bitmap_size) perf_score *= 2; else if (q->bitmap_size * 0.75 > avg_bitmap_size) perf_score *= 1.5; else if (q->bitmap_size * 3 < avg_bitmap_size) perf_score *= 0.25; else if (q->bitmap_size * 2 < avg_bitmap_size) perf_score *= 0.5; else if (q->bitmap_size * 1.5 < avg_bitmap_size) perf_score *= 0.75;
- 如果q->handicap大于等于4
- perf_score乘4.
- q->handicap减4.
- 否则,若q->handicap不为0
- perf_score乘2.
- q->handicap减1.
- 通过深度来调整
switch (q->depth)
{ //通过深度来调整perf_score
case 0 ... 3:
break;
case 4 ... 7:
perf_score *= 2;
break;
case 8 ... 13:
perf_score *= 3;
break;
case 14 ... 25:
perf_score *= 4;
break;
default:
perf_score *= 5;
}
- 最后确保调整后的值不会超过最大的接线
if (perf_score > HAVOC_MAX_MULT * 100)
perf_score = HAVOC_MAX_MULT * 100;- return perf_score
common_fuzz_stuff(char *argv, u8 out_buf, u32 len)
写入文件执行后判断执行返回结果。
- 如果设置了post_handler
- 调用
post_handler(out_buf, &len),返回out_buf - 若out_buf为0或len为0,return 0,如果需要对变异完的queue,最一层包装在写入的时候非常有用;
- 调用
- 调用
write_to_testcase写出out_buf run_target运行要fuzz的程序,返回fault。- 如果设置了stop_soon,直接返回1
- 如果fault等于FAULT_TMOUT
subseq_tmouts计数加一- 如果大于TMOUT_LIMIT(250)
- cur_skipped_paths计数加一后return 1;
- 否则令
subseq_tmouts = 0/用户可以使用 SIGUSR1 来请求当前输入被抛弃。/ - 如果设置skip_requested
- 归零
skip_requested subseq_tmouts计数加一- return 1;
- 归零
- 接下来处理FAULT_ERROR
save_if_interesting检测我们在run_target中运行的文件返回的结果是否是“有趣的”。- 返回值加上
queued_discovered成为新的queued_discovered
- 根据运行的轮数来输出fuzz统计信息。
- return 0;
魏姐姐好棒棒
hahaha