

Leveraging Textual Specifications for Grammar-Based Fuzzing of Network Protocols (AAAI 2019)
摘要
基于语法的模糊化是一种通过注入格式良好的输入来发现软件漏洞的技术,输入生成的规则对应用程序语义进行编码。
大多数基于语法的网络协议模糊器依赖于人类专家手动指定这些规则。
研究从文本规范(即RFC)自动学习协议规则,通过将自动提取的协议规则应用于最先进的传输协议模糊器来评估这些规则,结果表明,与使用手动指定规则的系统比较,它会使用更少的测试用例发现相同的漏洞数量。
目标
从现有文本文档中自动学习协议规则来提高基于语法的网络协议模糊器的覆盖率和有效性
(1)最大限度地减少学习所需的手动监督工作
(2)在不重新学习的情况下适应新协议。
(通过应用“现成”NLP工具来依赖NLP技术的最新进展,也可能由于领域差异而导致性能降低和应用程序脆弱。这些工具的性能(通常是经过新闻专线数据培训的))
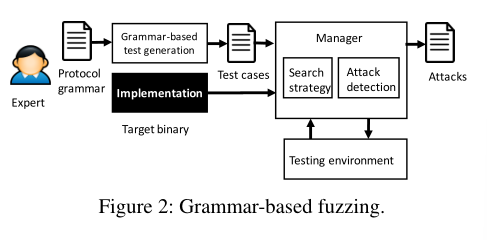
实现
(1)将协议语法提取问题定义为一组NLP任务。语法用于捕获相关方面,由协议的头字段及其属性组成。
(2)作者评估这些任务的NLP框架,减少适应新网络协议时的手动监控工作。与之前将转换规则直接应用于NLP工具输出的工作不同,作者提出了一个轻量级的零次学习框架,可以适应网络领域的特定属性。
(3)通过将NLP框架提取的信息应用到传输协议模糊器中,作者证明了它的有用性。作者比较了它在两种传输协议上使用手动和自动提取的协议信息时的性能,发现自动生成的协议语法在识别攻击方面与手动创建的语法一样有效,同时通常能够提高效率。
问题
基于协议语法的模糊化
对于网络协议,输入由数据包组成,规则表示协议语义,例如数据包头字段的属性和它们之间的关系。
协议语法提取
网络协议由附加到传输数据包的报头定义。该标题通常具有固定大小(以位为单位),其中某些部分(称为字段)具有定义的含义和大小。协议语义由这些字段的属性定义。例如,TCP报头中的字节17-18包含校验和。
通过两个组件定义协议语法:一组与报头相对应的字段,每个字段在报头中具有名称、大小(即#位)和顺序,以及一组可选字段属性。
两个NLP任务:
- 类型提取(给定一个协议文档,提取协议字段和属性符号集)
- 符号识别和链接(给定文档和提取的符号集,识别文本中对这些符号的提及,并将字段提及链接到它们的相关属性,如协议文本所示)
具体实现
- 预处理步骤,读取原始规范文档并规范它们的结构。
- 实体类型提取任务:利用协议规范文档(如RFC)的层次结构。作者使用基于规则的系统,利用RFC特定的格式来识别和提取实体类型。平均每个协议有25种类型,基于规则的系统能够以0.82的准确度恢复这些类型。
- 符号识别任务:作者采用两步方法,首先定位文档中提到的字段(实体),然后通过检查它们的上下文,寻找与它们相关的属性。【对于这两个步骤,作者都使用ZSL方法,其中分类器经过训练,以查找文档文本和协议符号之间的相似性。作者开发了基于网络协议数据的新分类器,而不是使用为非技术领域培训的现成工具,这些工具不适合我们的高技术领域。最后,后处理步骤将提取的信息转换为协议语法描述,可供下游数据包生成任务使用。】
- 属性提取:作者识别实体的属性,并从文档体中提取它们。基于对各种网络协议的分析,作者选择了9个属性进行提取。作者考虑的属性包括校验和,它标记包含校验和的包字段;端口,标记用于多路复用不同通信信道的数据包字段;和multiple,这表示字段的值是是某个常数的倍数。【作者在每个协议中寻找相同的属性。】